
RECONOCIMIENTO AUTOMÁTICO DEL HABLA
El Reconocimiento Automático del Habla (RAH), también conocido como Reconocimiento automático de voz, es una parte esencial de la Inteligencia Artificial y tiene como finalidad la comunicación hablada entre seres humanos y computadoras. El gran problema de este sistema es el de analizar adecuadamente un conjunto de informaciones que proceden de diferentes fuentes de conocimiento (léxica, sintáctica, semántica, pragmática, acústica, fonética y fonológica), teniendo en cuenta que pueden existir ambigüedades, incertidumbres y errores para llegar a conseguir una interpretación apropiada del mensaje acústico recibido.
Definición Los sistemas de RAH son sistemas muy recientes, y aunque han existido diferentes enfoques desde que surgieron siempre han proporcionado mejores resultados los sistemas probabilísticos, los cuales están basados en la “Teoría de la Decisión de Bayes”, la “Teoría de la información” y las “Técnicas de Comparación de Patrones y de Programación Dinámica”. Un sistema de RAH tiene que ser capaz de decodificar los sonidos u otra información de alto nivel que forman parte de un mensaje acústico. Dicha decodificación puede realizarse de diferentes formas, utilizando diferentes técnicas y con unos determinados requisitos iniciales para el mensaje a decodificar, es decir, consiste en generar un conjunto de patrones que puedan ser comparados con el mensaje (acústico) de entrada (a reconocer) devolviendo una secuencia de los patrones que con mayor probabilidad "representan" al mismo.
El Reconocimiento Automático del Habla (RAH), también conocido como Reconocimiento automático de voz, es una parte esencial de la Inteligencia Artificial y tiene como finalidad la comunicación hablada entre seres humanos y computadoras. El gran problema de este sistema es el de analizar adecuadamente un conjunto de informaciones que proceden de diferentes fuentes de conocimiento (léxica, sintáctica, semántica, pragmática, acústica, fonética y fonológica), teniendo en cuenta que pueden existir ambigüedades, incertidumbres y errores para llegar a conseguir una interpretación apropiada del mensaje acústico recibido.
Definición Los sistemas de RAH son sistemas muy recientes, y aunque han existido diferentes enfoques desde que surgieron siempre han proporcionado mejores resultados los sistemas probabilísticos, los cuales están basados en la “Teoría de la Decisión de Bayes”, la “Teoría de la información” y las “Técnicas de Comparación de Patrones y de Programación Dinámica”. Un sistema de RAH tiene que ser capaz de decodificar los sonidos u otra información de alto nivel que forman parte de un mensaje acústico. Dicha decodificación puede realizarse de diferentes formas, utilizando diferentes técnicas y con unos determinados requisitos iniciales para el mensaje a decodificar, es decir, consiste en generar un conjunto de patrones que puedan ser comparados con el mensaje (acústico) de entrada (a reconocer) devolviendo una secuencia de los patrones que con mayor probabilidad "representan" al mismo.
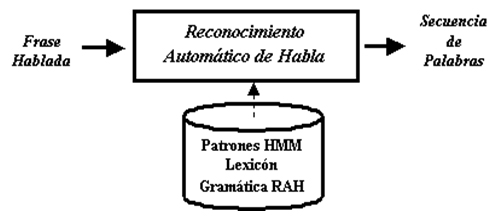
El proceso de RAH intenta conseguir la secuencia de palabras correspondientes a la frase en lenguaje natural de entrada. La frase es pronunciada de forma continua, sin pausas entre las palabras, por lo que genera problemas de agramaticalidad, además en las frases se incluyen elementos espontáneos como las interjecciones, falsos comienzos, repeticiones… Por todo ello, la tarea del estos sistemas no es sencilla,siendo además bastante costosa,tanto en concepto de memoria como de cálculo.
Historia del reconocimiento de voz
1870's Alexander Graham Bell:
Quería construir un sistema/dispositivo que hiciera el habla visible a las personas con problemas auditivos. Resultado: el teléfono
1880's Tihamir Nemes:
Solicita permiso para una patente para desarrollar un sistema de transcripción automática que identificara secuencias de sonidos y los imprimiera (texto). Pero fue rechazado como "Proyecto no Realista"
*30 años después AT&T Bell Laboratorios:
Construye la primera máquina capaz de reconocer voz (basada en Templates) de los 10 dígitos del inglés. Requería extenso reajuste a la voz de una persona, pero una vez logrado tenía un 99% de certeza. Por lo tanto surge la esperanza de que el reconocimiento de voz es simple y directo.
*A mediados de los 60’s:
La mayoría de los investigadores reconoce que era un proceso mucho más intrincado y sutil de lo que habían anticipado. Por lo tanto empiezan a reducir los alcances y se enfocan a sistemas más específicos:
Dependientes del Locutor.
Flujo discreto de habla (con espacios / pausas entre palabras)
Vocabulario pequeño (menor o igual a 50 palabras)
Estos sistemas empiezan a incorporar técnicas de normalización del tiempo (minimizar diferencia en velocidad del habla)
Además, ya no buscaban una exactitud perfecta en el reconocimiento.
Después:
IBM y CMV trabajan en reconocimiento de voz continuo pero no se ven resultados hasta los 1970's.
Principios 1970’s: se produce el 1er Producto de reconocimiento de voz, el VIP100 de Threshold Technology Inc. (utilizaba un vocabulario pequeño, dependiente del locutor, y reconocía palabras discretas). Gana el U.S. National Award en 1972.
Luego:
Nace el interés de ARPA del U.S. Department of Defense, y gracias al lanzamiento de grandes proyectos de investigacióny financiamiento por parte del gobierno se precipita la época de la inteligencia artificial.
El proyecto financiado por ARPA busca el reconocimiento de habla contínua, de vocabulario grande. Impulsa que los investigadores se enfoquen al entendimiento del habla.
Los sistemas empiezan a incorporar módulos de:
Análisis léxico (conocimiento léxico)
Análisis sintáctico (Estructura de Palabras)
Análisis semántico (Significado)
Análisis pragmático (Intención)
Este proyectos (el más grande es de los años 70’s) termina en 1976 con el resultado de que CMU, SRI, MIT crearon sistemas para el proyecto ARPA SUR (Speech Understanding Research).
80's a 90's:
Surgen los sistemas de vocabulario amplio, que ahora son la norma. (Más de1000 palabras). Adicionalmente bajan los precios de estos sistemas.
El Problema del Reconocimiento Automático del Habla La gran dificultad de estos sistemas es determinar cuáles pueden ser las causas que hacen tan difícil realizar un reconocimiento automático del habla, de forma que se pueda encontrar una solución global lo más óptima posible. Algunas de las causas son:
· Las variaciones de fonación, debidas a los hablantes. Cada persona pronuncia de forma diferente, ninguna persona habla igual, es decir, no suenan igual los sonidos generados por distintas personas, aunque mantienen ciertas relaciones formánticas, no son copias idénticas.
· Las ambigüedades acústicas. En algunas ocasiones, la misma señal acústica recibida se puede ajustar a dos patrones diferentes, esto se refiere a palabras que se pronuncian igual pero se escriben de forma distinta (vaca y baca).
· Variaciones de producción y que le desvían del registro teórico ideal, como puede ser:
· Falta de cuidado al pronunciar algunas palabras. En algunas ocasiones se omiten palabras de breve duración o se combinan con otras, originando sonidos extraños. También se suele producir cuando el hablante adquiere demasiada velocidad al pronunciar las palabras, provocando que la transición entre las diferentes silabas no sea lo suficientemente clara, llegando a la fusión u omisión de alguna palabra.
· Variación en la pronunciación. A lo largo del tiempo se van produciendo diferentes formas de pronunciación, lo que produce un alejamiento de los patrones o reglas utilizadas durante el reconocimiento.
· Coarticulación. La señal acústica recibida se ve afectada debido al contexto en el que se encuentra. Debido a esto es necesario disponer de diferentes patrones que consideren estas posibles variaciones.
· Variaciones de tiempo. La duración de la pronunciación de una palabra no tiene un tiempo determinado, sino que depende del emisor, con la rapidez que hable, debido a esto la comparación entre los patrones puede verse afectada por lo que hay que tenerla en cuenta antes de comparar.
· Ruidos e interferencias. Las personas somos capaces de reconocer habla en condiciones desfavorables, es decir, en las que existen una baja reacción señal/ruido, e incluso si existen otros sonidos interfiriendo. Esto se debe a las características del oído humano.
Debido a los problemas anteriormente descritos, la tarea de reconocimiento automático de habla tiene que tomar decisiones, incluso a pesar de la falta de información, sabiendo que todas las decisiones que tome influirán en las siguientes. El hecho de tomar decisiones repercute gravemente en el sistema total, ya que además de tener que utilizar alguna técnica para que tome estas decisiones es necesaria alguna técnica de corrección de errores, ya que no todas las decisiones tomadas serán correctas.
Para minimizar la probabilidad de cometer errores podemos utilizar “La Teoría de la Decisión Estadística”, la cual consiste en valorar distintas secuencias de palabras y tomar como válida la que tenga mayor probabilidad de estar asociada a la secuencia acústica de entrada. Con el fin de minimizar el problema también se puede emplear el “Teorema de Bayes” sobre la probabilidad condicional, de forma que el problema anterior se puede volver a escribir de modo que la búsqueda de la secuencia de palabras se conviertan en un problema de buscar la secuencia de palabras que producen un máximo de probabilidad a priori y que además, producen la secuencia de observaciones con máxima probabilidad. De esta forma el problema está dividido en dos, un problema de decodificación lingüística y otro de decodificación acústica.
Sistemas de Reconocimiento Automático del Habla existentes Desde el año 1990 existen sistemas comerciales basados en el reconocimiento de voz. Sin embargo, son pocos los usuarios que utilizan sistemas de este tipo en sus ordenadores. Es en las aplicaciones telefónicas donde se suele utilizar con más frecuencia este tipo de sistemas: agencias de viajes, atención al cliente, información etc. Los programas comerciales más famosos basados en el reconocimiento automático del habla son:
· Sistemas de dictado(dependientes del locutor, es decir, reconocen el habla de una persona determinada):
· Speech Magic (Philips Speech Recognition Systems): Plataforma cuyo fin es proporcionar capacidades para el reconocimiento del habla a clínicas, hospitales y consultas médicas.
· Via Voice de IBM: Programa de reconocimiento del habla comercializado por IBM que permite transformar en texto las palabras que vaya dictando una determinada persona. Para llevar a cabo la transformación, va a ser necesaria la utilización de un micrófono.
· Dragon Naturally Speaking: Programa que permite que el computador escriba en varios formatos todo aquello que vaya reconociendo mediante la voz.
· Philips FreeSpeechun: Software que permite reconocer la voz,y que sirve para hacerle un dictado al procesador de texto.
· Sistemas telefónicos (independientes del locutor, es decir reconocen el habla de cualquier persona): Son un importante campo de las tecnologías del habla. Constituyen una nueva forma de interacción entre el teléfono y el usuario. Un ejemplo de ello es el software vocal de Telefónica.
· Indexado de medios de comunicación:
· Media Mining Indexer de Sail Labs Technology: Producto de gama alta de reconocimiento de voz que permite automatizar el proceso de detección de archivos multimedia en tiempo real y transmisiones de noticias en vivo.
Historia del reconocimiento de voz
1870's Alexander Graham Bell:
Quería construir un sistema/dispositivo que hiciera el habla visible a las personas con problemas auditivos. Resultado: el teléfono
1880's Tihamir Nemes:
Solicita permiso para una patente para desarrollar un sistema de transcripción automática que identificara secuencias de sonidos y los imprimiera (texto). Pero fue rechazado como "Proyecto no Realista"
*30 años después AT&T Bell Laboratorios:
Construye la primera máquina capaz de reconocer voz (basada en Templates) de los 10 dígitos del inglés. Requería extenso reajuste a la voz de una persona, pero una vez logrado tenía un 99% de certeza. Por lo tanto surge la esperanza de que el reconocimiento de voz es simple y directo.
*A mediados de los 60’s:
La mayoría de los investigadores reconoce que era un proceso mucho más intrincado y sutil de lo que habían anticipado. Por lo tanto empiezan a reducir los alcances y se enfocan a sistemas más específicos:
Dependientes del Locutor.
Flujo discreto de habla (con espacios / pausas entre palabras)
Vocabulario pequeño (menor o igual a 50 palabras)
Estos sistemas empiezan a incorporar técnicas de normalización del tiempo (minimizar diferencia en velocidad del habla)
Además, ya no buscaban una exactitud perfecta en el reconocimiento.
Después:
IBM y CMV trabajan en reconocimiento de voz continuo pero no se ven resultados hasta los 1970's.
Principios 1970’s: se produce el 1er Producto de reconocimiento de voz, el VIP100 de Threshold Technology Inc. (utilizaba un vocabulario pequeño, dependiente del locutor, y reconocía palabras discretas). Gana el U.S. National Award en 1972.
Luego:
Nace el interés de ARPA del U.S. Department of Defense, y gracias al lanzamiento de grandes proyectos de investigacióny financiamiento por parte del gobierno se precipita la época de la inteligencia artificial.
El proyecto financiado por ARPA busca el reconocimiento de habla contínua, de vocabulario grande. Impulsa que los investigadores se enfoquen al entendimiento del habla.
Los sistemas empiezan a incorporar módulos de:
Análisis léxico (conocimiento léxico)
Análisis sintáctico (Estructura de Palabras)
Análisis semántico (Significado)
Análisis pragmático (Intención)
Este proyectos (el más grande es de los años 70’s) termina en 1976 con el resultado de que CMU, SRI, MIT crearon sistemas para el proyecto ARPA SUR (Speech Understanding Research).
80's a 90's:
Surgen los sistemas de vocabulario amplio, que ahora son la norma. (Más de1000 palabras). Adicionalmente bajan los precios de estos sistemas.
El Problema del Reconocimiento Automático del Habla La gran dificultad de estos sistemas es determinar cuáles pueden ser las causas que hacen tan difícil realizar un reconocimiento automático del habla, de forma que se pueda encontrar una solución global lo más óptima posible. Algunas de las causas son:
· Las variaciones de fonación, debidas a los hablantes. Cada persona pronuncia de forma diferente, ninguna persona habla igual, es decir, no suenan igual los sonidos generados por distintas personas, aunque mantienen ciertas relaciones formánticas, no son copias idénticas.
· Las ambigüedades acústicas. En algunas ocasiones, la misma señal acústica recibida se puede ajustar a dos patrones diferentes, esto se refiere a palabras que se pronuncian igual pero se escriben de forma distinta (vaca y baca).
· Variaciones de producción y que le desvían del registro teórico ideal, como puede ser:
· Falta de cuidado al pronunciar algunas palabras. En algunas ocasiones se omiten palabras de breve duración o se combinan con otras, originando sonidos extraños. También se suele producir cuando el hablante adquiere demasiada velocidad al pronunciar las palabras, provocando que la transición entre las diferentes silabas no sea lo suficientemente clara, llegando a la fusión u omisión de alguna palabra.
· Variación en la pronunciación. A lo largo del tiempo se van produciendo diferentes formas de pronunciación, lo que produce un alejamiento de los patrones o reglas utilizadas durante el reconocimiento.
· Coarticulación. La señal acústica recibida se ve afectada debido al contexto en el que se encuentra. Debido a esto es necesario disponer de diferentes patrones que consideren estas posibles variaciones.
· Variaciones de tiempo. La duración de la pronunciación de una palabra no tiene un tiempo determinado, sino que depende del emisor, con la rapidez que hable, debido a esto la comparación entre los patrones puede verse afectada por lo que hay que tenerla en cuenta antes de comparar.
· Ruidos e interferencias. Las personas somos capaces de reconocer habla en condiciones desfavorables, es decir, en las que existen una baja reacción señal/ruido, e incluso si existen otros sonidos interfiriendo. Esto se debe a las características del oído humano.
Debido a los problemas anteriormente descritos, la tarea de reconocimiento automático de habla tiene que tomar decisiones, incluso a pesar de la falta de información, sabiendo que todas las decisiones que tome influirán en las siguientes. El hecho de tomar decisiones repercute gravemente en el sistema total, ya que además de tener que utilizar alguna técnica para que tome estas decisiones es necesaria alguna técnica de corrección de errores, ya que no todas las decisiones tomadas serán correctas.
Para minimizar la probabilidad de cometer errores podemos utilizar “La Teoría de la Decisión Estadística”, la cual consiste en valorar distintas secuencias de palabras y tomar como válida la que tenga mayor probabilidad de estar asociada a la secuencia acústica de entrada. Con el fin de minimizar el problema también se puede emplear el “Teorema de Bayes” sobre la probabilidad condicional, de forma que el problema anterior se puede volver a escribir de modo que la búsqueda de la secuencia de palabras se conviertan en un problema de buscar la secuencia de palabras que producen un máximo de probabilidad a priori y que además, producen la secuencia de observaciones con máxima probabilidad. De esta forma el problema está dividido en dos, un problema de decodificación lingüística y otro de decodificación acústica.
Sistemas de Reconocimiento Automático del Habla existentes Desde el año 1990 existen sistemas comerciales basados en el reconocimiento de voz. Sin embargo, son pocos los usuarios que utilizan sistemas de este tipo en sus ordenadores. Es en las aplicaciones telefónicas donde se suele utilizar con más frecuencia este tipo de sistemas: agencias de viajes, atención al cliente, información etc. Los programas comerciales más famosos basados en el reconocimiento automático del habla son:
· Sistemas de dictado(dependientes del locutor, es decir, reconocen el habla de una persona determinada):
· Speech Magic (Philips Speech Recognition Systems): Plataforma cuyo fin es proporcionar capacidades para el reconocimiento del habla a clínicas, hospitales y consultas médicas.
· Via Voice de IBM: Programa de reconocimiento del habla comercializado por IBM que permite transformar en texto las palabras que vaya dictando una determinada persona. Para llevar a cabo la transformación, va a ser necesaria la utilización de un micrófono.
· Dragon Naturally Speaking: Programa que permite que el computador escriba en varios formatos todo aquello que vaya reconociendo mediante la voz.
· Philips FreeSpeechun: Software que permite reconocer la voz,y que sirve para hacerle un dictado al procesador de texto.
· Sistemas telefónicos (independientes del locutor, es decir reconocen el habla de cualquier persona): Son un importante campo de las tecnologías del habla. Constituyen una nueva forma de interacción entre el teléfono y el usuario. Un ejemplo de ello es el software vocal de Telefónica.
· Indexado de medios de comunicación:
· Media Mining Indexer de Sail Labs Technology: Producto de gama alta de reconocimiento de voz que permite automatizar el proceso de detección de archivos multimedia en tiempo real y transmisiones de noticias en vivo.
Supercomputadora Watson

Watson es una tecnología cognitiva que procesa la información más como un ser humano que un ordenador-mediante la comprensión del lenguaje natural, la generación de hipótesis basadas en la evidencia y el aprendizaje de lo que va.
Watson es un sistema informático de inteligencia artificial que es capaz de responder a preguntas formuladas en lenguaje natural, desarrollado por la corporación estadounidense IBM. Forma parte del proyecto del equipo de investigación DeepQA, liderado por el investigador principal David Ferrucci. Lleva su nombre en honor del fundador y primer presidente de IBM, Thomas J. Watson.
Watson responde a las preguntas gracias a una base de datos almacenada localmente. La información contenida en ese base de datos proviene de multitud de fuentes, incluyendo enciclopedias, diccionarios, tesauros, artículos de noticias, y obras literarias, al igual que bases de datos externos, taxonomías, y ontologías (específicamente DBpedia, WordNet, y Yago).
La Banca del Futuro: Software para el Reconocimiento de Voz
El avance más prometedor recogido por MIT Technology Review se trata de un nuevo método para verificar la identificación de personas mediante un sistema de comprobación de la autenticidad de voz y realización de preguntas personales. Este avance tecnológico patentado por IBM pretende reducir el número de transacciones telefónicas fraudulentas. Normalmente cuando un cliente llama a su banco para realizar alguna transacción, un mensaje grabado le pide su número de identificación, y un operador le hace una pregunta personal para verificar su identidad. Otro método utilizado por bancos consiste en un sistema de reconocimiento automático de la voz, pero estos sistemas pueden tener problemas con ruidos causados por interferencias o incluso con alguna variación natural en la voz del cliente en cuestión. IBM ha logrado combinar e integrar ambos métodos para crear un nuevo sistema de protección contra el fraude, en su opinión muy superior a cualquiera de los sistemas individuales. El sistema de IBM crea un archivo, a través de la grabación de una "huella de voz" (una muestra de la voz del cliente), además de la grabación de sus contestaciones a una serie de preguntas personales. Cuando el cliente llama al banco, el sistema recoge tanto su voz como la contestación que ofrece a la pregunta personal, los compara y si son iguales que las muestras y contestaciones grabadas en su archivo, le permite acceder a los servicios bancarios que solicita. Además, introduce una mayor variedad de preguntas personales, incluyendo información sobre las últimas transacciones realizadas, y crea un sistema de preguntas al azar, para que sea más difícil acceder a los servicios bancarios a través de la grabación ilegal de accesos telefónicos anteriores.
IBM espera sacar el sistema al mercado dentro de pocos años. Esta innovación aplicada a otras vertientes (gestión de las administraciones públicas, tramitaciones administrativas en general...) en el caso de superar las restricciones legales, supondría un sustancial avance en la agilización de trámites sin el requerimiento de la presencia física.
El reconocimiento de voz para las personas con discapacidades.
Uno de los mayores impactos de la tecnología de reconocimiento de voz, se da en la educación, de personas con algún tipo de discapacidad. Los estudiantes con discapacidad, que posee un control limitado, sobre las computadoras, se encuentran en una situación de desventaja. Pero, con la tecnología de reconocimiento de voz, tienen una herramienta eficaz para controlar el equipo y ser tan productivos como sus compañeros que no poseen ninguna discapacidad. El reconocimiento de voz se utiliza para convertir sus ideas en texto. Para los estudiantes con discapacidades, el hecho de ver sus pensamientos e ideas convertidas en texto, es un refuerzo para el uso de sus capacidades orales de vocabulario. El reconocimiento de voz es también una bendición para los adultos que sufren algún tipo de discapacidad. El hecho de poder manejar una computadora, le permite tener una serie de herramientas a su deposición que mejorarán su calidad de vida. No hay ninguna razón por la que no puedan participar en debates en línea, chats, blogs, video juegos, y mucho más. El objetivo de la tecnología de reconocimiento de voz, es el de mejorar la experiencia del usuario y aumentar los niveles de accesibilidad a las computadoras. El reconocimiento de voz y otras herramientas de accesibilidad esencialmente proporcionan una igualdad de condiciones en el uso de las computadoras. Los beneficios del uso de estas tecnologías, en la vida diaria de muchas personas, son más que obvios.
Técnicas más utilizadas aplicadas al Reconocimiento del Habla
Las técnicas que más se utilizan en el reconocimiento automático del habla son:
Técnicas de Programación Dinámica (DTW) Esta técnica consiste en realizar una comparación entre los patrones o plantillas de las que dispone el sistema con la señal acústica recibida como entrada, de esta forma se obtienen posibles candidatos a los que puede pertenecer la señal recibida. Para realizar esta tarea tan compleja se parametriza la señal recibida y se transforma la señal de entrada en coeficientes espectrales para analizarla de forma correcta. Una vez se obtiene los espectros de la señal comienza el proceso de reconocimiento comparándolo con los patrones almacenados. Esta técnica, es utilizada tanto para resolver problemas de reconocimiento de habla continua como aislada. Sin embargo esta técnica suele tener algunos problemas debido a: la duración de la palabra no tiene que ser de una duración determinada, por lo que puede que no coincida con la de la plantilla; y el ritmo con el que se realiza la pronunciación no tiene que mantenerse constante por lo que no se ajustará a la plantilla en ese sentido, ya que este depende de la persona.
Modelos Ocultos de Markov (HMM) Un modelo oculto de Markov se puede considerar como una especie de autómata finito, ya que está formado por una serie de estados que tienen una conexión directa mediante transiciones. El proceso va a dar comienzo en un estado inicial, específicamente diseñado para ello, y cada uno de los estados va a tener asociado un conjunto de probabilidades sobre un grupo de símbolos salientes. Por cada una de las ejecuciones, se va a elegir una transición hacia un estado nuevo, y se va a generar un símbolo de salida relacionado con dicho estado. La elección en cada ejecución de cada transición y símbolo se va realizar en función de probabilidades, y por tanto va a ser una elección completamente aleatoria. La característica principal de los modelos de Markov es no se va a conocer nunca el conjunto de estados por los que el proceso ha realizado el recorrido hasta llegar al conjunto de símbolos obtenidos en la salida, y este es el motivo fundamental por el que se le conoce como Modelo oculto de Markov. Al aplicar los modelos ocultos de Markov al reconocimiento del habla, cada estado va a indicar cuáles son aquellos sonidos que son más probables para cada segmento del habla, mientras que las transiciones van a ser restricciones temporales para cada uno de esos sonidos, indicando cuáles son sus secuencias de apariciones.
Redes Neuronales El estudio de las redes neuronales fue abandonado prácticamente desde que aparecieran, debido a que no se podía llevar a cabo su entrenamiento con algoritmos que fuesen eficientes. Sin embargo, en la actualidad ha quedado perfectamente demostrado que los modelos basados en las redes neuronales cuentan con una gran potencia desde el punto de vista computacional. Las redes neuronales son una estructura de procesamiento y aprendizaje de información, que está formada por un conjunto de nodos que se denominan neuronas, las cuales están conectadas mediante una serie de pesos. Cada neurona va a recibir una entrada a partir de las conexiones que tiene con el resto de neuronas, y va a producir una salida. Gracias a las ventajas que tienen (capacidad de aprendizaje, tolerancia ante fallos, capacidad de producir respuestas en tiempo real...),las redes neuronales han pasado a ser una de las mejores soluciones para abordar el problema del reconocimiento automático del habla. Sin embargo, los sistemas basados en redes neuronales también tienen algunos inconvenientes como puede ser el elevado tiempo de entrenamiento necesario o el desconocimiento previo del número de nodos que se necesitan para abordar un problema. Esto implica que se haga necesario combinar dichos sistemas con técnicas basadas en programación dinámica y en modelos ocultos de Markov.
Clasificación de los Sistemas de Reconocimiento Automático del Habla Los sistemas de reconocimiento de voz se pueden clasificar atendiendo a los siguientes criterios:
· Entrenabilidad: Indica si va a ser necesario o no entrenar al sistema para comenzar con su uso.
· Dependencia del hablante: Va a determinar si el sistema es apto para funcionar con una única persona (en este caso se denomina dependiente del locutor) o por el contrario es apto para funcionar con cualquier persona(es independiente del locutor).Los sistemas independientes del locutor son sistemas con una mayor calidad, aunque sin embargo suelen ser más difíciles de llevar a cabo, y además presentan un precio más alto en el mercado.
· Continuidad: Determina si el sistema está capacitado para reconocer un tipo de habla que se realice de forma continua (sistemas continuos) o por el contrario es necesario que el usuario realice paradas entre la pronunciación de cada una de las palabras, para que así el sistema las pueda reconocer. Los sistemas continuos y funcionan sobre un lenguaje en el que las palabras están conectadas, es decir, no están separadas por pausas. En general, los sistemas continuos van a ser más difíciles de desarrollar, ya que estos sistemas se ven afectados por la rapidez con la que se pronuncia el discurso; mientras más rápido se pronuncie una frase, más complejo va a ser detectar el inicio y el fin de una palabra en esa frase. Por el contrario, los sistemas discretos van a ser más fáciles de diseñar, ya que se realizan paros entre cada palabra; de esta forma, una palabra no se va a ver afectada por la forma en que se pronuncie otra palabra, por tanto va a ser más fácil encontrar el inicio y fin de cada una de las palabras en la frase, y en definitiva, va a ser más fácil realizar su reconocimiento.
· Robustez: Determina si el diseño del sistema es apto o no para su funcionamiento en condiciones de ruido extremo.
· Tamaño del dominio: Indica si el sistema puede llevar a cabo el reconocimiento de un lenguaje con un determinado tamaño de dominio. Existen sistemas con un vocabulario de tamaño reducido, y otros en cambio con vocabularios muy extensos. Podemos clasificar los vocabularios atendiendo a su tamaño en:
· Vocabularios pequeños: Contienen decenas de palabras.
· Vocabularios medianos: Contienen cientos de palabras.
· Vocabularios grandes: Contienen miles de palabras.
· Vocabularios muy grandes: Contienen decenas de miles de palabras.
· Arquitectura: Según la arquitectura que tenga cada sistema de reconocimiento automático del habla, los vamos a poder clasificar en:
· Sistemas de Arquitectura Integrada: Van a realizar el reconocimiento en una única etapa. Estos sistemas van a generar espacios de búsqueda más grandes que los sistemas de arquitectura no integrada, pero sin embargo van a tener una posibilidad más alta de encontrar una solución correcta.
· Sistemas de Arquitectura no Integrada: Estos sistemas van a dividir el reconocimiento de una frase en 2 etapas: una primera etapa en la que se van a extraer una serie de sonidos a partir de la frase de entrada, y una segunda etapa que va a devolver aquellas frases que mejor se adapten a los sonidos obtenidos en la primera etapa. Estos sistemas generan espacios de búsqueda más pequeños que los sistemas de arquitectura integrada, pero su probabilidad de error a la hora de encontrar la solución correcta va a ser mayor.
Diseño de un sistema de RAH Los sistemas actuales de Reconocimiento Automático del Habla (RAH) se componen de varias etapas en las que se pueden utilizar distintos tipos de metodologías:
Watson es un sistema informático de inteligencia artificial que es capaz de responder a preguntas formuladas en lenguaje natural, desarrollado por la corporación estadounidense IBM. Forma parte del proyecto del equipo de investigación DeepQA, liderado por el investigador principal David Ferrucci. Lleva su nombre en honor del fundador y primer presidente de IBM, Thomas J. Watson.
Watson responde a las preguntas gracias a una base de datos almacenada localmente. La información contenida en ese base de datos proviene de multitud de fuentes, incluyendo enciclopedias, diccionarios, tesauros, artículos de noticias, y obras literarias, al igual que bases de datos externos, taxonomías, y ontologías (específicamente DBpedia, WordNet, y Yago).
La Banca del Futuro: Software para el Reconocimiento de Voz
El avance más prometedor recogido por MIT Technology Review se trata de un nuevo método para verificar la identificación de personas mediante un sistema de comprobación de la autenticidad de voz y realización de preguntas personales. Este avance tecnológico patentado por IBM pretende reducir el número de transacciones telefónicas fraudulentas. Normalmente cuando un cliente llama a su banco para realizar alguna transacción, un mensaje grabado le pide su número de identificación, y un operador le hace una pregunta personal para verificar su identidad. Otro método utilizado por bancos consiste en un sistema de reconocimiento automático de la voz, pero estos sistemas pueden tener problemas con ruidos causados por interferencias o incluso con alguna variación natural en la voz del cliente en cuestión. IBM ha logrado combinar e integrar ambos métodos para crear un nuevo sistema de protección contra el fraude, en su opinión muy superior a cualquiera de los sistemas individuales. El sistema de IBM crea un archivo, a través de la grabación de una "huella de voz" (una muestra de la voz del cliente), además de la grabación de sus contestaciones a una serie de preguntas personales. Cuando el cliente llama al banco, el sistema recoge tanto su voz como la contestación que ofrece a la pregunta personal, los compara y si son iguales que las muestras y contestaciones grabadas en su archivo, le permite acceder a los servicios bancarios que solicita. Además, introduce una mayor variedad de preguntas personales, incluyendo información sobre las últimas transacciones realizadas, y crea un sistema de preguntas al azar, para que sea más difícil acceder a los servicios bancarios a través de la grabación ilegal de accesos telefónicos anteriores.
IBM espera sacar el sistema al mercado dentro de pocos años. Esta innovación aplicada a otras vertientes (gestión de las administraciones públicas, tramitaciones administrativas en general...) en el caso de superar las restricciones legales, supondría un sustancial avance en la agilización de trámites sin el requerimiento de la presencia física.
El reconocimiento de voz para las personas con discapacidades.
Uno de los mayores impactos de la tecnología de reconocimiento de voz, se da en la educación, de personas con algún tipo de discapacidad. Los estudiantes con discapacidad, que posee un control limitado, sobre las computadoras, se encuentran en una situación de desventaja. Pero, con la tecnología de reconocimiento de voz, tienen una herramienta eficaz para controlar el equipo y ser tan productivos como sus compañeros que no poseen ninguna discapacidad. El reconocimiento de voz se utiliza para convertir sus ideas en texto. Para los estudiantes con discapacidades, el hecho de ver sus pensamientos e ideas convertidas en texto, es un refuerzo para el uso de sus capacidades orales de vocabulario. El reconocimiento de voz es también una bendición para los adultos que sufren algún tipo de discapacidad. El hecho de poder manejar una computadora, le permite tener una serie de herramientas a su deposición que mejorarán su calidad de vida. No hay ninguna razón por la que no puedan participar en debates en línea, chats, blogs, video juegos, y mucho más. El objetivo de la tecnología de reconocimiento de voz, es el de mejorar la experiencia del usuario y aumentar los niveles de accesibilidad a las computadoras. El reconocimiento de voz y otras herramientas de accesibilidad esencialmente proporcionan una igualdad de condiciones en el uso de las computadoras. Los beneficios del uso de estas tecnologías, en la vida diaria de muchas personas, son más que obvios.
Técnicas más utilizadas aplicadas al Reconocimiento del Habla
Las técnicas que más se utilizan en el reconocimiento automático del habla son:
Técnicas de Programación Dinámica (DTW) Esta técnica consiste en realizar una comparación entre los patrones o plantillas de las que dispone el sistema con la señal acústica recibida como entrada, de esta forma se obtienen posibles candidatos a los que puede pertenecer la señal recibida. Para realizar esta tarea tan compleja se parametriza la señal recibida y se transforma la señal de entrada en coeficientes espectrales para analizarla de forma correcta. Una vez se obtiene los espectros de la señal comienza el proceso de reconocimiento comparándolo con los patrones almacenados. Esta técnica, es utilizada tanto para resolver problemas de reconocimiento de habla continua como aislada. Sin embargo esta técnica suele tener algunos problemas debido a: la duración de la palabra no tiene que ser de una duración determinada, por lo que puede que no coincida con la de la plantilla; y el ritmo con el que se realiza la pronunciación no tiene que mantenerse constante por lo que no se ajustará a la plantilla en ese sentido, ya que este depende de la persona.
Modelos Ocultos de Markov (HMM) Un modelo oculto de Markov se puede considerar como una especie de autómata finito, ya que está formado por una serie de estados que tienen una conexión directa mediante transiciones. El proceso va a dar comienzo en un estado inicial, específicamente diseñado para ello, y cada uno de los estados va a tener asociado un conjunto de probabilidades sobre un grupo de símbolos salientes. Por cada una de las ejecuciones, se va a elegir una transición hacia un estado nuevo, y se va a generar un símbolo de salida relacionado con dicho estado. La elección en cada ejecución de cada transición y símbolo se va realizar en función de probabilidades, y por tanto va a ser una elección completamente aleatoria. La característica principal de los modelos de Markov es no se va a conocer nunca el conjunto de estados por los que el proceso ha realizado el recorrido hasta llegar al conjunto de símbolos obtenidos en la salida, y este es el motivo fundamental por el que se le conoce como Modelo oculto de Markov. Al aplicar los modelos ocultos de Markov al reconocimiento del habla, cada estado va a indicar cuáles son aquellos sonidos que son más probables para cada segmento del habla, mientras que las transiciones van a ser restricciones temporales para cada uno de esos sonidos, indicando cuáles son sus secuencias de apariciones.
Redes Neuronales El estudio de las redes neuronales fue abandonado prácticamente desde que aparecieran, debido a que no se podía llevar a cabo su entrenamiento con algoritmos que fuesen eficientes. Sin embargo, en la actualidad ha quedado perfectamente demostrado que los modelos basados en las redes neuronales cuentan con una gran potencia desde el punto de vista computacional. Las redes neuronales son una estructura de procesamiento y aprendizaje de información, que está formada por un conjunto de nodos que se denominan neuronas, las cuales están conectadas mediante una serie de pesos. Cada neurona va a recibir una entrada a partir de las conexiones que tiene con el resto de neuronas, y va a producir una salida. Gracias a las ventajas que tienen (capacidad de aprendizaje, tolerancia ante fallos, capacidad de producir respuestas en tiempo real...),las redes neuronales han pasado a ser una de las mejores soluciones para abordar el problema del reconocimiento automático del habla. Sin embargo, los sistemas basados en redes neuronales también tienen algunos inconvenientes como puede ser el elevado tiempo de entrenamiento necesario o el desconocimiento previo del número de nodos que se necesitan para abordar un problema. Esto implica que se haga necesario combinar dichos sistemas con técnicas basadas en programación dinámica y en modelos ocultos de Markov.
Clasificación de los Sistemas de Reconocimiento Automático del Habla Los sistemas de reconocimiento de voz se pueden clasificar atendiendo a los siguientes criterios:
· Entrenabilidad: Indica si va a ser necesario o no entrenar al sistema para comenzar con su uso.
· Dependencia del hablante: Va a determinar si el sistema es apto para funcionar con una única persona (en este caso se denomina dependiente del locutor) o por el contrario es apto para funcionar con cualquier persona(es independiente del locutor).Los sistemas independientes del locutor son sistemas con una mayor calidad, aunque sin embargo suelen ser más difíciles de llevar a cabo, y además presentan un precio más alto en el mercado.
· Continuidad: Determina si el sistema está capacitado para reconocer un tipo de habla que se realice de forma continua (sistemas continuos) o por el contrario es necesario que el usuario realice paradas entre la pronunciación de cada una de las palabras, para que así el sistema las pueda reconocer. Los sistemas continuos y funcionan sobre un lenguaje en el que las palabras están conectadas, es decir, no están separadas por pausas. En general, los sistemas continuos van a ser más difíciles de desarrollar, ya que estos sistemas se ven afectados por la rapidez con la que se pronuncia el discurso; mientras más rápido se pronuncie una frase, más complejo va a ser detectar el inicio y el fin de una palabra en esa frase. Por el contrario, los sistemas discretos van a ser más fáciles de diseñar, ya que se realizan paros entre cada palabra; de esta forma, una palabra no se va a ver afectada por la forma en que se pronuncie otra palabra, por tanto va a ser más fácil encontrar el inicio y fin de cada una de las palabras en la frase, y en definitiva, va a ser más fácil realizar su reconocimiento.
· Robustez: Determina si el diseño del sistema es apto o no para su funcionamiento en condiciones de ruido extremo.
· Tamaño del dominio: Indica si el sistema puede llevar a cabo el reconocimiento de un lenguaje con un determinado tamaño de dominio. Existen sistemas con un vocabulario de tamaño reducido, y otros en cambio con vocabularios muy extensos. Podemos clasificar los vocabularios atendiendo a su tamaño en:
· Vocabularios pequeños: Contienen decenas de palabras.
· Vocabularios medianos: Contienen cientos de palabras.
· Vocabularios grandes: Contienen miles de palabras.
· Vocabularios muy grandes: Contienen decenas de miles de palabras.
· Arquitectura: Según la arquitectura que tenga cada sistema de reconocimiento automático del habla, los vamos a poder clasificar en:
· Sistemas de Arquitectura Integrada: Van a realizar el reconocimiento en una única etapa. Estos sistemas van a generar espacios de búsqueda más grandes que los sistemas de arquitectura no integrada, pero sin embargo van a tener una posibilidad más alta de encontrar una solución correcta.
· Sistemas de Arquitectura no Integrada: Estos sistemas van a dividir el reconocimiento de una frase en 2 etapas: una primera etapa en la que se van a extraer una serie de sonidos a partir de la frase de entrada, y una segunda etapa que va a devolver aquellas frases que mejor se adapten a los sonidos obtenidos en la primera etapa. Estos sistemas generan espacios de búsqueda más pequeños que los sistemas de arquitectura integrada, pero su probabilidad de error a la hora de encontrar la solución correcta va a ser mayor.
Diseño de un sistema de RAH Los sistemas actuales de Reconocimiento Automático del Habla (RAH) se componen de varias etapas en las que se pueden utilizar distintos tipos de metodologías:
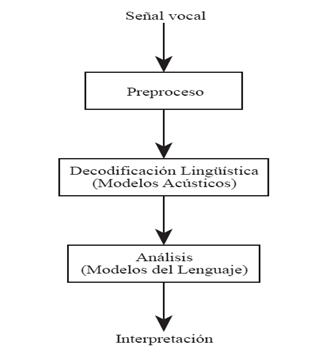
Los
objetivos de la primera etapa son llevar a cabo la adquisición de la señal
vocal y posteriormente extraer aquellas características que se consideren más
importantes (Preproceso). Como resultado, a la salida de esta etapa se va a
obtener una secuencia de vectores de características o cadenas de símbolos que
pertenecerán a un determinado alfabeto. La segunda etapa tiene como objetivo el
encontrar e identificar en la señal vocal segmentos de voz que guarden relación
con algún patrón o unidad lingüística (fonemas, sílabas, palabras,...). Esta
etapa es conocida como Decodificación Lingüística o Decodificación
Acústico-Fonética, y su salida va a ser una o más secuencias de unidades
lingüísticas que van a contener varios errores. La tercera etapa (Análisis) va
a tener como principal objetivo realizar una interpretación de las secuencias
de unidades lingüísticas obtenidas en la etapa anterior, corrigiendo los
errores, y devolviendo sólo aquellas secuencias que se consideren correctas
desde el punto de vista sintáctico y semántico.
Aprendizaje Cada una de las etapas descritas requiere la existencia de una serie de modelos que deben ser construidos en una fase de aprendizaje. Este aprendizaje se puede llevar a cabo de forma deductiva e inductiva. El aprendizaje deductivo consiste en que una persona experta le transmita al sistema informático una serie de conocimientos. En este aspecto podemos poner como ejemplo los Sistemas Expertos. El aprendizaje inductivo consiste en que sea el propio sistema informático el que adquiera los conocimientos de forma automática, a partir de una serie de ejemplos reales. Serían ejemplos de este tipo de aprendizaje aquellos sistemas que se basan en los modelos ocultos de Markov o en las redes neuronales artificiales que se configuran de forma automática tomando como referencia una serie de ejemplos de aprendizaje.
Decodificador acústico-fonético El decodificador acústico-fonético es originado por las fuentes de información léxica, fonética, acústica y fonológica, junto con una serie de procedimientos interpretativos. La entrada al decodificador acústico-fonético es la propia señal acústica representada mediante un vector de características, una vez que ésta ha pasado por la etapa de preproceso. A la hora de diseñar un decodificador acústico-fonético nos pueden surgir ciertos problemas para los cuales no existen soluciones que puedan solventarlos. Primeramente, está el problema de elegir cuáles son las unidades subléxicas que se consideran más idóneas. En la actualidad, las semisílabas y las sílabas pueden ser buenas soluciones, aunque las más utilizadas son ciertas unidades fonéticas. Y en segundo lugar, otro de los problemas que podemos tener a la hora de diseñar un decodificador acústico-fonético es el de la modelización y coarticulación de palabras cortas que pueden cambiar totalmente la interpretación de un mensaje acústico.
Modelo del lenguaje El modelo del lenguaje va a estar formado por las fuentes de conocimiento sintácticas, pragmáticas y semánticas. El objetivo va a ser realizar una correcta interpretación desde estos tres puntos de vista. Al igual que en el caso del decodificador acústico-fonético, a la hora de diseñar un modelo del lenguaje van a surgir una serie de problemas de difícil solución. Primero, hay que decir que en la actualidad, se tiende a que la sintaxis y la semántica estén integradas, lo cual representa un problema a la hora de representarlas. Esto se debe fundamentalmente a que los sistemas de reconocimiento del habla presentan grandes restricciones de tipo semántico y sintáctico, lo que implica que existan fuertes lazos de unión entre ambas. Las medidas principales que se están tomando al respecto provienen del campo de los lenguajes formales y del lenguaje natural. Y en segundo lugar, otros problemas son el uso del diálogo y la prosodia (acentos, tonos, entonación) entre la propia persona y el sistema de reconocimiento.
Interacción del Sistema de Reconocimiento y el Sistema de Comprensión Un sistema de reconocimiento de habla puede utilizar diferentes formas para interactuar con el sistema de procesamiento de lenguaje natural (sistema de comprensión). El modo más sencillo para realizar esta comunicación se basaría en reconocer la frase hablada por el sistema de reconocimiento, haciendo únicamente uso de la información acústica. Una vez que se obtenga la mejor hipótesis, ésta será la entrada al sistema de comprensión, que solo se basará en la información textual. Las ventajas que representa este proceso son: una mínima interacción entre los especialistas de reconocimiento del habla y los de procesamiento del lenguaje natura, y la capacidad de integrar ambos sistemas en uno, formando el sistema de comprensión del habla. A pesar de estas ventajas, este proceso no obtiene resultados óptimos, se debe a que ambos sistemas son independientes y no comparten la información que utilizan independientemente. De esta forma una frase que es reconocida con errores tiene escasas opciones de ser interpretada de forma adecuada, ya que esta información no es completada con conocimiento lingüístico (sintáctico, semántico, etc). Para mejorar los resultados de éste proceso no solo se pasa la mejor frase, sino un conjunto de las frases mejor valoradas, de esta forma se pretende aumentar la calidad de la información que recibe el sistema de comprensión, aunque no disminuye el número de errores, ahora pueden solucionarse a partir de las otras frases recibidas.
El Problema de la Eficiencia (Reducción del Espacio de Búsqueda) Un buen sistema de reconocimiento debe ser capaz de reconocer habla continua con vocabularios medios y grandes, para que este proceso sea eficiente se deben considerar las distintas posibilidades que pueden reducir los espacios de búsqueda tan grandes que se generan. Para ello se puede utilizar el algoritmo de Viterbi, el cual es un algoritmo de búsqueda en anchura capaz de encontrar una solución óptima, que junto con técnicas capaces de reducir el espacio de búsqueda (“beam search”, búsqueda en haz) consiguen reducir suficientemente los costes computacionales y de memoria de forma muy significativa, consiguiendo que el proceso sea eficiente.
Usos y aplicaciones Las tareas más comunes en las que se utiliza el reconocimiento de voz en un ordenador son:
· Dictado: Consiste en aplicaciones en las cuales el usuario dicta al computador y este redacta un documento con el texto que va reconociendo del habla del usuario. Se suelen utilizar diccionarios específicos de un tema para aumentar la precisión del reconocedor. Este es el uso más común de todos.
· Control por voz: Consisten en dar órdenes a un computador, son frases cortas de pocas palabras (normalmente dos, comando y aplicación), como por ejemplo: "Abrir editor", "Cerrar editor", "Avanzar canción", etc. Estos reconocedores suelen tener un vocabulario muy escaso lo que incrementa sus posibilidades de acierto.
· Servicios de telefonía: La mayoría de los operadores telefónicos ofrecen servicios en los cuales interviene un reconocedor de voz, cuando se debe seleccionar una opción permite que la hagas con la voz sin necesidad de tener que pulsar una tecla. Normalmente se indica al usuario que seleccione la opción indicando un número con la voz.
· Sistemas portables: Son sistemas muy pequeños. Su uso habitual se realiza en los teléfonos móviles para interactuar con el dispositivo, como por ejemplo la marcación por voz que ofrecen algunos teléfonos móviles.
· Sistemas para discapacitados: Estos sistemas pueden ayudar bastante a algunas personas con algún tipo de discapacidad, por ejemplo a personas con problemas auditivos le permitiría hablar por teléfono, ya que la voz que recibe por el terminal sería proporcionada al ordenador que mediante el reconocedor de voz escribiría la frase recibida.
Además de poder realizar estas tareas se puede utilizar para realizar cualquier otra en la que sea necesario interactuar con el ordenador.
Bibliografía
Reconocimiento Automático del Habla. (marzo de 2014). Recuperado el 02 de ABRIL de 2014, de Epistemowikia: http://cala.unex.es/cala/epistemowikia/index.php?title=Reconocimiento_Autom%C3%A1tico_del_Habla
bejerano, p. g. (01 de diciembre de 2013). Cómo funciona un sistema de reconocimiento de voz. Recuperado el 2 de abril de 2014, de http://www.eldiario.es/turing/reconocimiento-voz-biometria_0_201230680.html
IBM. (2014). What Is Watson? Recuperado el 02 de abril de 2014, de http://www.ibm.com/smarterplanet/us/en/ibmwatson/
Llisterri, J. (18 de marzo de 2014). El reconocimiento automático del habla. Recuperado el 02 de abril de 2014, de Departament de Filologia Espanyola, Universitat Autònoma de Barcelona: http://liceu.uab.es/~joaquim/speech_technology/tecnol_parla/recognition/speech_recognition/reconocimiento.html
Ministerio de Educación, C. y. (31 de marzo de 2009). Reconocimiento y Síntesis de voz. Recuperado el 02 de abril de 2014, de http://recursostic.educacion.es/observatorio/web/ca/software/software-general/689-reconocimiento-y-sintesis-de-voz
Aprendizaje Cada una de las etapas descritas requiere la existencia de una serie de modelos que deben ser construidos en una fase de aprendizaje. Este aprendizaje se puede llevar a cabo de forma deductiva e inductiva. El aprendizaje deductivo consiste en que una persona experta le transmita al sistema informático una serie de conocimientos. En este aspecto podemos poner como ejemplo los Sistemas Expertos. El aprendizaje inductivo consiste en que sea el propio sistema informático el que adquiera los conocimientos de forma automática, a partir de una serie de ejemplos reales. Serían ejemplos de este tipo de aprendizaje aquellos sistemas que se basan en los modelos ocultos de Markov o en las redes neuronales artificiales que se configuran de forma automática tomando como referencia una serie de ejemplos de aprendizaje.
Decodificador acústico-fonético El decodificador acústico-fonético es originado por las fuentes de información léxica, fonética, acústica y fonológica, junto con una serie de procedimientos interpretativos. La entrada al decodificador acústico-fonético es la propia señal acústica representada mediante un vector de características, una vez que ésta ha pasado por la etapa de preproceso. A la hora de diseñar un decodificador acústico-fonético nos pueden surgir ciertos problemas para los cuales no existen soluciones que puedan solventarlos. Primeramente, está el problema de elegir cuáles son las unidades subléxicas que se consideran más idóneas. En la actualidad, las semisílabas y las sílabas pueden ser buenas soluciones, aunque las más utilizadas son ciertas unidades fonéticas. Y en segundo lugar, otro de los problemas que podemos tener a la hora de diseñar un decodificador acústico-fonético es el de la modelización y coarticulación de palabras cortas que pueden cambiar totalmente la interpretación de un mensaje acústico.
Modelo del lenguaje El modelo del lenguaje va a estar formado por las fuentes de conocimiento sintácticas, pragmáticas y semánticas. El objetivo va a ser realizar una correcta interpretación desde estos tres puntos de vista. Al igual que en el caso del decodificador acústico-fonético, a la hora de diseñar un modelo del lenguaje van a surgir una serie de problemas de difícil solución. Primero, hay que decir que en la actualidad, se tiende a que la sintaxis y la semántica estén integradas, lo cual representa un problema a la hora de representarlas. Esto se debe fundamentalmente a que los sistemas de reconocimiento del habla presentan grandes restricciones de tipo semántico y sintáctico, lo que implica que existan fuertes lazos de unión entre ambas. Las medidas principales que se están tomando al respecto provienen del campo de los lenguajes formales y del lenguaje natural. Y en segundo lugar, otros problemas son el uso del diálogo y la prosodia (acentos, tonos, entonación) entre la propia persona y el sistema de reconocimiento.
Interacción del Sistema de Reconocimiento y el Sistema de Comprensión Un sistema de reconocimiento de habla puede utilizar diferentes formas para interactuar con el sistema de procesamiento de lenguaje natural (sistema de comprensión). El modo más sencillo para realizar esta comunicación se basaría en reconocer la frase hablada por el sistema de reconocimiento, haciendo únicamente uso de la información acústica. Una vez que se obtenga la mejor hipótesis, ésta será la entrada al sistema de comprensión, que solo se basará en la información textual. Las ventajas que representa este proceso son: una mínima interacción entre los especialistas de reconocimiento del habla y los de procesamiento del lenguaje natura, y la capacidad de integrar ambos sistemas en uno, formando el sistema de comprensión del habla. A pesar de estas ventajas, este proceso no obtiene resultados óptimos, se debe a que ambos sistemas son independientes y no comparten la información que utilizan independientemente. De esta forma una frase que es reconocida con errores tiene escasas opciones de ser interpretada de forma adecuada, ya que esta información no es completada con conocimiento lingüístico (sintáctico, semántico, etc). Para mejorar los resultados de éste proceso no solo se pasa la mejor frase, sino un conjunto de las frases mejor valoradas, de esta forma se pretende aumentar la calidad de la información que recibe el sistema de comprensión, aunque no disminuye el número de errores, ahora pueden solucionarse a partir de las otras frases recibidas.
El Problema de la Eficiencia (Reducción del Espacio de Búsqueda) Un buen sistema de reconocimiento debe ser capaz de reconocer habla continua con vocabularios medios y grandes, para que este proceso sea eficiente se deben considerar las distintas posibilidades que pueden reducir los espacios de búsqueda tan grandes que se generan. Para ello se puede utilizar el algoritmo de Viterbi, el cual es un algoritmo de búsqueda en anchura capaz de encontrar una solución óptima, que junto con técnicas capaces de reducir el espacio de búsqueda (“beam search”, búsqueda en haz) consiguen reducir suficientemente los costes computacionales y de memoria de forma muy significativa, consiguiendo que el proceso sea eficiente.
Usos y aplicaciones Las tareas más comunes en las que se utiliza el reconocimiento de voz en un ordenador son:
· Dictado: Consiste en aplicaciones en las cuales el usuario dicta al computador y este redacta un documento con el texto que va reconociendo del habla del usuario. Se suelen utilizar diccionarios específicos de un tema para aumentar la precisión del reconocedor. Este es el uso más común de todos.
· Control por voz: Consisten en dar órdenes a un computador, son frases cortas de pocas palabras (normalmente dos, comando y aplicación), como por ejemplo: "Abrir editor", "Cerrar editor", "Avanzar canción", etc. Estos reconocedores suelen tener un vocabulario muy escaso lo que incrementa sus posibilidades de acierto.
· Servicios de telefonía: La mayoría de los operadores telefónicos ofrecen servicios en los cuales interviene un reconocedor de voz, cuando se debe seleccionar una opción permite que la hagas con la voz sin necesidad de tener que pulsar una tecla. Normalmente se indica al usuario que seleccione la opción indicando un número con la voz.
· Sistemas portables: Son sistemas muy pequeños. Su uso habitual se realiza en los teléfonos móviles para interactuar con el dispositivo, como por ejemplo la marcación por voz que ofrecen algunos teléfonos móviles.
· Sistemas para discapacitados: Estos sistemas pueden ayudar bastante a algunas personas con algún tipo de discapacidad, por ejemplo a personas con problemas auditivos le permitiría hablar por teléfono, ya que la voz que recibe por el terminal sería proporcionada al ordenador que mediante el reconocedor de voz escribiría la frase recibida.
Además de poder realizar estas tareas se puede utilizar para realizar cualquier otra en la que sea necesario interactuar con el ordenador.
Bibliografía
Reconocimiento Automático del Habla. (marzo de 2014). Recuperado el 02 de ABRIL de 2014, de Epistemowikia: http://cala.unex.es/cala/epistemowikia/index.php?title=Reconocimiento_Autom%C3%A1tico_del_Habla
bejerano, p. g. (01 de diciembre de 2013). Cómo funciona un sistema de reconocimiento de voz. Recuperado el 2 de abril de 2014, de http://www.eldiario.es/turing/reconocimiento-voz-biometria_0_201230680.html
IBM. (2014). What Is Watson? Recuperado el 02 de abril de 2014, de http://www.ibm.com/smarterplanet/us/en/ibmwatson/
Llisterri, J. (18 de marzo de 2014). El reconocimiento automático del habla. Recuperado el 02 de abril de 2014, de Departament de Filologia Espanyola, Universitat Autònoma de Barcelona: http://liceu.uab.es/~joaquim/speech_technology/tecnol_parla/recognition/speech_recognition/reconocimiento.html
Ministerio de Educación, C. y. (31 de marzo de 2009). Reconocimiento y Síntesis de voz. Recuperado el 02 de abril de 2014, de http://recursostic.educacion.es/observatorio/web/ca/software/software-general/689-reconocimiento-y-sintesis-de-voz
